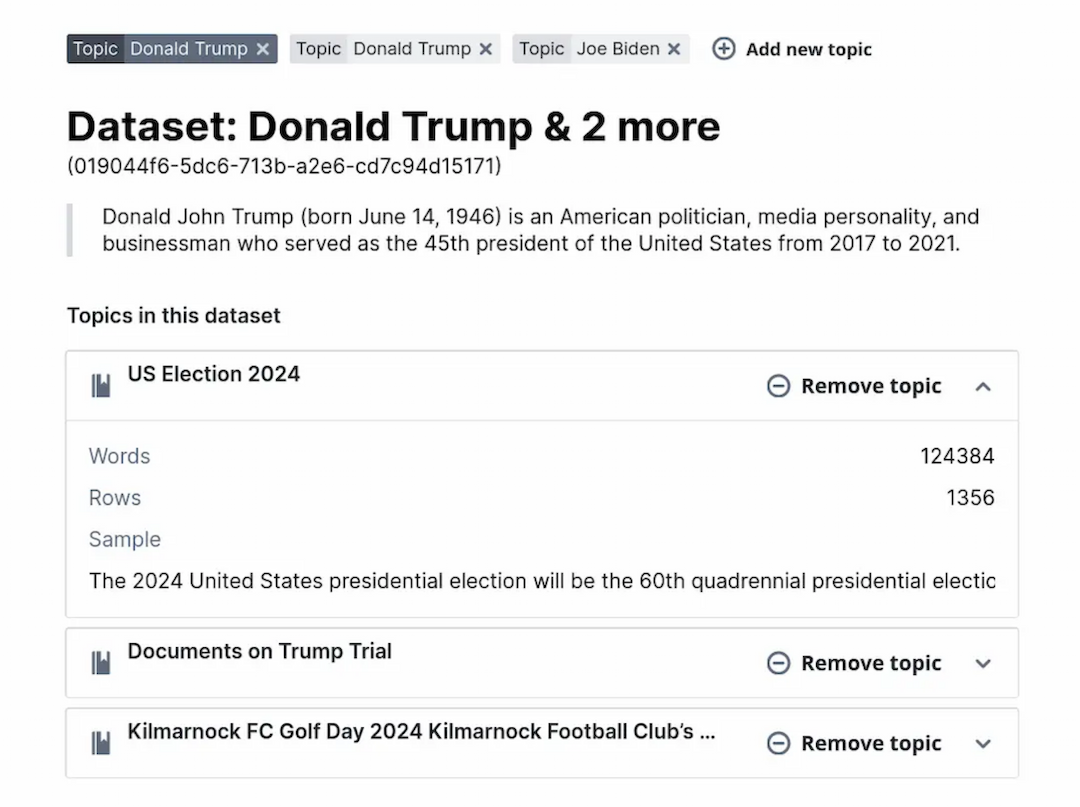
Curate the data that you want on a per-topic basis
We source, filter and index a variety of datasets from public, proprietary and licensed sources. Our data is web-scale and alone our searchable index of Common Crawl/FineWeb attributes to more than 15 Trillion subwords (tokens). This data has been pre processed, filtered and scored for its usefulness and quality (read more) and is updated every 3 months. Each update amounts to roughly 400 GB of fine text data and is fully searchable by topic. We additionally add the world’s news and Wikipedia updates to the data on a daily basis. This allows for a “quasi complete knowledge base” of what is happening in the world and includes many more resources from economics to education to engineering and code.
Semantic index
Select the data you care about by searching for topics or describing your dataset.
Web scale datasets
Access a more than 10 trillion words of deduplicated and high quality web-data.
Transparent pricing
Your training cost is determined by the amount of words trained.
Deploy your workload
Self-host or use our cloud to productize your AI and serve to end-users.
Find your data
Datasets at Tofu AI can be searched by the topics the are supposed to represent. By calculating vector embeddings for all data we can match the semantic meaning of every text in a high dimensional vector space with your request.